Abstract
Modern video diffusion transformers place tokens on a 2D pixel grid and encode their positions (e.g., RoPE over the u, v, t axes). These encodings describe the camera's sampling grid rather than the 3D structure of the scene. RayPE injects per-token Plücker coordinates additively into the queries and keys of self-attention; a query/key flip makes the Euclidean inner product reduce to the Plücker reciprocal product even at zero learning, providing a built-in 3D inductive bias. A Normalize-Gate-Inject design decouples ray direction from ray-moment magnitude. The module adds <0.1% parameters, is zero-initialized, and coexists with the original RoPE rather than replacing it.
Key Ideas
- A video frame samples a light field. The natural coordinate of a ray is its 6D Plücker representation, and the geometry between two rays is the Plücker reciprocal product — bilinear in the two rays, the same algebraic form as the attention dot product.
- Geometry inside the dot product. A query/key flip makes the Euclidean inner product reduce to the Plücker reciprocal product even at zero learning, giving the attention a built-in 3D inductive bias instead of forcing the model to recover correspondence from pixels alone.
- Robust across data. A Normalize-Gate-Inject design decouples ray direction from ray-moment magnitude, so the encoding stays well-scaled across datasets with very different camera-translation scales.
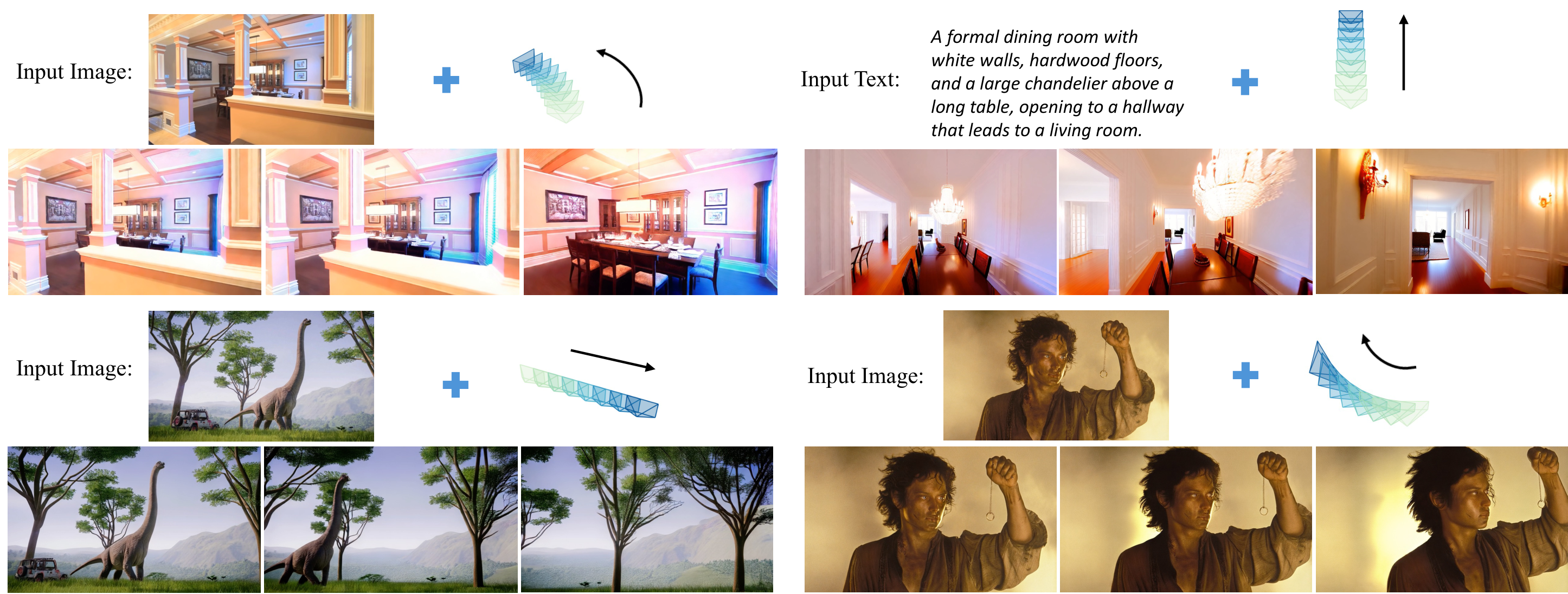
Scenes
One generated scene browsed under six different camera trajectories. The inset visualizes the commanded camera path.
Motions
WASD inputs drive the camera trajectory that moves the third-person subject. Overlay keys reflect the per-frame motion.
Real-World Scenes
Diverse real captures driven along varied camera paths from a single frame.
In-the-Wild Videos
Everyday footage re-rendered under controllable camera motion.
Stylized & Artistic Scenes
Illustrated and painterly inputs animated with 3D-consistent camera control.